エンタープライズアイデンティティおよびアクセス管理
この記事は https://docs.evolveum.com/iam/enterprise-iam/ の翻訳です。
はじめに
アイデンティティおよびアクセス管理 (IAM) とは何でしょうか。この問いへの答えは簡単でもあり、非常に複雑でもあります。 簡単に言えば、IAM はサイバースペースにおけるアイデンティティの管理に関わるすべてです。 複雑な答えは、この文書の残り全体を占めます。
この文書は、エンタープライズ、金融機関、政府機関、大学、医療機関など、より大きな組織に適用されるアイデンティティおよびアクセス管理である エンタープライズアイデンティティおよびアクセス管理 を扱います。 焦点は、従業員、請負業者、パートナー、学生、その他組織と協働する人々の管理です。 一部の概念は一般的に適用できますが、この文書はインターネットアイデンティティ (ユーザー中心または消費者向けアイデンティティとも呼ばれるもの) や政府アイデンティティ (G2C の意味でのもの) に焦点を当てているわけではありません。
ユーザーアカウント
アイデンティティおよびアクセス管理の中心概念は、通常、人物に関するデータの集合を含むデータ記録です。 この概念には多くの名前がありますが、最も一般的なのはアカウント、ペルソナ、ユーザー記録、ユーザーアイデンティティです。 アカウントには通常、人物の名や姓など、現実世界の人物を説明する情報が含まれます。 しかしおそらく最も重要なのは、そのアカウントが作成される情報システムの操作に関わる技術的な情報です。 これにはホームディレクトリの指定、グループやロールメンバーシップなどの多様な権限情報、システムリソース制限などが含まれます。 ユーザーアカウントは集中化され、統合されている場合も、分散し、そろっていない場合も、その両極端の中間である場合もあります。 しかしアーキテクチャにかかわらず、アイデンティティ管理の目的はアカウントの管理です。
アイデンティティおよびアクセス管理技術
アイデンティティおよびアクセス管理は単一の技術ではありません。 実際には、互いに補完し、同時に重なり合うさまざまな技術の混合体です。 アイデンティティ管理には少なくとも3つの主要な技術分野があります。
- アイデンティティストア はユーザーアカウント情報を保存します。 通常、アイデンティティストアはネットワーク越しに他システムへ公開され、多数のアプリケーションに共有されると想定されますが、常にそうとは限りません。 LDAP ディレクトリサーバー、Active Directory、リレーショナルデータベースの一部はアイデンティティストアの例です。
- アイデンティティ管理 (IDM) は、アイデンティティストアの管理に焦点を当てる IAM 技術の分野です。 IDM システムは、幅広いデータ形式、モデル、意味、目的にわたってアカウントデータを同期する複雑な機構です。 IDM システムには通常、高度な式とルールエンジン、ワークフロー機構、ポリシー評価と強制などが含まれます。 アイデンティティガバナンス は、アイデンティティ管理の業務側面に焦点を当てるアイデンティティ管理の拡張です。
- アクセス管理 (AM) は、ユーザー認証と、部分的には認可を扱います。 アクセス管理の目的は、ユーザーが特定のシステムや機能にアクセスするときに発生するセキュリティ機構を統一することです。 シングルサインオン (SSO) は、アクセス管理の一部と見なされることがあります。
これらの技術は形式上、アイデンティティ管理という単一の分野を構成しますが、その目的と方法は大きく異なります。 複雑なアイデンティティ管理ソリューションでは、少なくともそれぞれの一部が必要になります。 これらの技術について、以下でより詳しく説明します。
アイデンティティストア
アカウントは アイデンティティストア と呼ばれるデータベースに保存されます。 これらのデータベースの基盤となる技術は、平文テキストファイルからリレーショナルデータベース、ディレクトリサーバーまでさまざまです。 特に LDAP プロトコルでアクセスされるディレクトリサーバーは、その拡張性のため非常に広く使われている。 アイデンティティストアは、それを使うアプリケーションと統合されている場合も、共有された独立型のシステムである場合もあります。
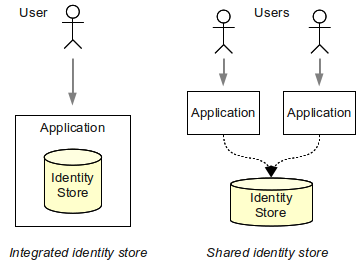
共有アイデンティティストアはユーザー管理を容易にします。 アカウントは1か所で作成・管理すればよくなります。 認証は各アプリケーションで個別に行われます。 しかしアプリケーションが共有ストアの同じ認証情報を使うため、ユーザーは接続されたすべてのアプリケーションで同じパスワードを使えます。
共有アイデンティティストアに基づくアイデンティティ管理ソリューションは単純で、かなり費用対効果が高いです。 しかし、そのようなソリューションの機能はかなり限定されます。
アイデンティティストアは文字通り情報の保存場所です。 このようなデータベースへアクセスするプロトコルと API は、主にデータベースインターフェイスとして設計されています。 つまり、データの保存、検索、取得には優れています。 アカウント内のデータにエンタイトルメント情報 (権限、グループ、ロールなど) が含まれる場合でも、アイデンティティストアはそれらを評価するのに適していません。 つまりアイデンティティストアはアカウントがどの権限を持つかという情報を提供できますが、特定の操作を許可するか拒否するかの 判断 はできません。 アイデンティティストアはユーザー セッション に関するデータも含みません。 つまりアイデンティティストアはユーザーが現在ログインしているかどうかを知りません。 一部のアイデンティティストア、特に LDAP ベースのディレクトリシステムは基本認証や認可に頻繁に使われます。 しかしストアはそのために設計されたものではなく、非常に基本的な機能しか提供しません。 アイデンティティストアはデータベースであり、認証サーバーや認可サーバーではありません。
メタディレクトリと仮想ディレクトリ
メタディレクトリは、複数の「通常の」ディレクトリシステムを同期する特殊なディレクトリシステムです。 メタディレクトリはデータをコピーします。 したがって、元の同期対象ディレクトリシステムの性能はほとんど影響を受けません。
仮想ディレクトリはプロキシでありプロトコル変換器です。 仮想ディレクトリは、複数の「通常の」ディレクトリサーバーから統合ビューを作成します。 メタディレクトリと異なり、データはコピーされません。 仮想ディレクトリは申請ごとに元のディレクトリからデータを取得し、それを統合ビューに変換します。
一部のメタディレクトリと仮想ディレクトリは、一般的なディレクトリの概念を越えることができます。たとえばリレーショナルデータベースの表からデータを取得できます。 メタディレクトリと仮想ディレクトリはどちらもデータを変換できます。 しかし、両者のデータ変換能力は非常に限定的です。 たとえば数値や日付形式は変換できますが、通常は複雑な処理を実行できません。 また、大きく異なるデータモデルを使う記録を同期することもできません。 エントリ相関付け能力はさらに限定されます。 したがってメタディレクトリと仮想ディレクトリは、非常に単純な導入にしか適していません。 これが、これらのディレクトリが現在あまり使われていない理由の1つかもしれません。
IDM システムは通常、メタディレクトリができることをすべて実行でき、はるかに柔軟です。 IDM システムは一定の条件下では仮想ディレクトリとして動作することもできます。 ただし IDM システムの性能は、通常メタディレクトリや仮想ディレクトリより劣ります。
単一アイデンティティストア神話
共有アイデンティティストアはユーザー管理を容易にしますが、これは完全なソリューションではなく、この方法には深刻な制約があります。 一般的な中規模から大規模のエンタープライズ環境における情報システムの異種混在性は、次の理由により単一ディレクトリシステムの実装をほぼ不可能にします。
- 単一で一貫した情報ソースの欠如。 1人のユーザーについて、通常は複数の情報ソースがあります。 たとえば HR システムは、エンタープライズ内にユーザーが存在することと従業員識別子の割り当てについて信頼できる情報源です。 管理情報システムはユーザーのロールの決定に責任を持ちます (例: プロジェクト指向の組織構造)。 在庫管理システムはユーザーへの電話番号割り当てに責任を持ちます。 グループウェアシステムはユーザーのメールアドレスやその他の電子連絡先データの信頼できるソースです。 通常、1人のユーザーについて信頼できる情報を提供するシステムは2から20あります。
- ローカルユーザーデータベースの必要性。 一部のシステムは、効率的に動作するためにユーザー記録のコピーをローカルデータベースに保存しなければなりません。 たとえば大規模課金システムは、外部データでは効率的に動作できません (たとえばリレーショナルデータベースの join ができないため)。 レガシーシステムは通常外部データにまったくアクセスできません (たとえば LDAP プロトコルをサポートしていません)。
- 状態を持つサービス。 一部のサービスは、動作するためにユーザーごとの状態を保持する必要があります。 たとえばファイルサーバーは通常ユーザーのホームディレクトリを作成します。 状態作成の自動化は通常オンデマンド (たとえばユーザーの初回ログオン時) にできますが、状態の修正と削除はずっと困難です。
- 一貫しないポリシー。 ロール名やアクセス制御属性は、すべてのシステムで同じ意味を持つとは限りません。 異なるシステムは通常、相互互換性のない異なる認可アルゴリズムを持っています。 この問題はアプリケーションごとのアクセス制御属性で解決できますが、これらの属性の維持管理は簡単ではないかもしれません。 アクセス制御属性 (通常はロール) を変換・維持管理する複雑ツールが必要になる場合があります。
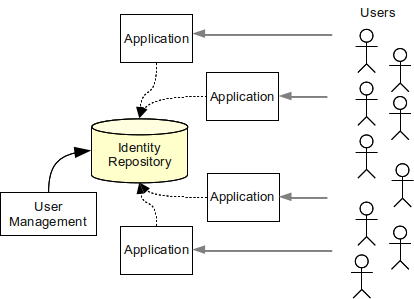
メタディレクトリや仮想ディレクトリ機構を使っても、期待した結果が得られない場合があります。これらのシステムはデータとプロトコル変換を提供するだけで、ディレクトリサービスの基本原則を変えないためです。 異種混在のシステム、特に大規模エンタープライズ環境においてユーザー記録を管理するには、より複雑な方法が必要です。
単一ディレクトリ方法が現実的なのは、非常に単純な環境またはほぼ完全に同質な環境だけです。 それ以外のすべての場合、他のアイデンティティ管理技術も使う必要があります。
アイデンティティストア実装
オープンソースアイデンティティストア実装には次のものがあります。
- OpenLDAP: C で書かれた高速な LDAP ディレクトリサーバー。
- 389 ディレクトリサーバー (a.k.a Fedora ディレクトリサーバー): 2000年代の旧 iPlanet ディレクトリサーバーに基づく、C で書かれたディレクトリサーバー。
- Apache ディレクトリサーバー: Java で書かれたディレクトリサーバー。
- OpenDJ: Java で書かれた LDAP ディレクトリサーバー。このプロジェクトはもう 維持管理 されていません。
- wren:DS: OpenDJ サーバーの fork。維持管理されているようですが、新機能開発はありません。
アイデンティティ管理
IDM システムは、多くの異なるアイデンティティストアを統合します。 IDM システムの目的は、アイデンティティストアを可能な限り、かつ実務的な範囲で同期された状態に保つことです。 IDM システムの priority は non-intrusive であることです。 IDM システムは、アプリケーション内の既存アカウントデータモデルを変更しようとはしません。 IDM システムは、接続された各システムのデータモデルに合わせて、自身の機構を適応させようとします。 そのため IDM システムはかなり複雑で、カスタマイズ可能かつプログラム可能 である必要があります。 データモデルの適応ation は、複雑なルールや式を使って行われることがよくあります。
IDM システムは既存のデータストアを管理するだけです。 アプリケーションに代わって認証や認可を行うわけでは ありません。それはアクセス管理の仕事です。 したがって IDM システムは、他システムのデータを操作することで、セキュリティポリシーの強制に間接的に影響します。 IDM 技術は、front-end に大きく影響することなく、アプリケーション back-end に焦点を当てます。
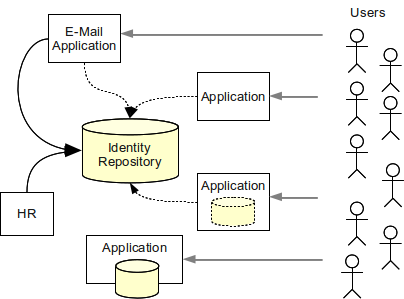
IDM コネクターとエージェント
IDM システムは、アプリケーション自身のプロトコルまたはインターフェイスを使って各アプリケーションと通信できます。 基本方法は2つあります。
- コネクター は IDM システム側で動作するコード片です。 この点ではデータベース driver に似ています。 コネクターはアプリケーションのオブジェクト (アカウント、グループ、ACL など) を IDM システムに公開します。 コネクターはその目的のために、さまざまな remote プロトコルや API を使います。 コネクターは non-intrusive であり、アプリケーション側への installation を必要としません。
- エージェント はアプリケーション側で動作します。 コネクターと同様、エージェントはアプリケーションのオブジェクトを IDM システムに公開します。 エージェントは intrusive であり、アプリケーション側への installation (および統合) が必要です。 ただしエージェントはローカル API も使えるため、コネクターよりはるかに強力な場合があります。
ポリシーとプロセス: ガバナンス
IDM システムは統合の技術的な 側面 だけを扱うわけではありません。 ポリシーとプロセスは、ほぼ常に IDM システム導入プロジェクトの一部です。 ほとんどの IDM システムには、アイデンティティ管理アプリケーション向けにカスタマイズされた独自版のワークフローサブシステムが含まれています。 新規採用者の基本アカウントを自動的に決定し、そのアカウント作成をシステム管理者に承認させるルールは、通常かなり簡単に設定できます。 ユーザーは追加の権限や権限を申請でき、それが付与される前に承認プロセスを通ることもあります。 一部の IDM システムはアクセス権限の再認定も可能にします。
これは、他の IAM 技術と比べたときの IDM システムの 独自の側面 です。 他の技術は通常、問題の技術的な side だけに焦点を当て、業務 side には焦点を当てません。 IDM システムは、アイデンティティ管理の業務 side と技術的な side を結び付ける glue です。
なぜアイデンティティ管理が必要なのか
そもそもなぜ IDM システムが必要なのでしょうか。LDAP サーバーのような単一で統合されたなアイデンティティストアを導入するだけの方が簡単ではないでしょうか。 はい、それは簡単です。 しかし、それが可能なのは非常に単純な状況だけです。 技術的なアーキテクチャが単一アイデンティティストア方法に適している場合でも、non-technical な課題は残ります。 たとえば単一アイデンティティストアは1日で現れるわけではありません。 その導入と統合には長い時間がかかる場合があります。 その間には IDM システムが必要です。 またアプリケーションは素早く適応できません。 たとえば多くのアプリケーションは LDAP 認証を 標準で でサポートします。 しかし LDAP 認証は非常に単純なアプリケーションにしか十分ではありません。 複雑アプリケーションは通常ローカルデータ記録、つまりアカウントを必要とします。 そのようなアカウントが認証情報 (パスワード) を含まない場合でも、中央アイデンティティストアには保存されていない認可データ (ロール、権限、組織上の単位メンバーシップ) を含みます。 他のアプリケーションは、レポートのためにデータベース join を行うなど、ローカルデータ記録を必要とします。 またアプリケーションが理論上単一アイデンティティストアで動作できるとしても、実務上それを動かすには何年もかかるかもしれません。 このような場合、IDM システムはより早く、しばしばより低費用でソリューションを提供できます。
IDM システムにおけるプロセスサポートも、このソリューションを支持する別の理由です。 アイデンティティストアは静的データを提示します。 しかし IDM システムはデータ変更を扱うことがよくあります。 したがって IDM システムは、変更が適用される前にその承認を enforce できます。 IDM システムはデータが変更された後に通知を送ることができます。 IDM システムは手作業プロセスをアイデンティティ管理ソリューションに統合することもできます (例: アイデンティティ管理を自動化できないレガシーシステム)。
アイデンティティ管理における RBAC
RBAC はロールベースのアクセス制御の略です。 権限と権限をロールに分類し、ロールをユーザーに割り当てる方法です。 このモデルは1990年代に形式的に定義され、多くの情報システムが内部的に RBAC をサポートしています。 しかし、その RBAC モデルは単一アプリケーションの内部に閉じ込められており、複数のアプリケーションにわたって機能させるのは簡単ではありません。 IDM システムはそれを行うためのツールです。 IDM システムは複数のアプリケーションにまたがるロールを作成できます。
RBAC は簡単で elegant なソリューションに見えるかもしれませんが、いくつかの欠点があります。 これらの課題は、IDM ソリューション導入中によく行われる enterprise-wide RBAC モデリング で特に問題になります。
通常、IDM 導入中に最初に遭遇する障害は RBAC モデルの incompatibility です。 RBAC モデルは単純で、複雑導入には単純すぎるかもしれません。 そのためアプリケーションは、職務上の位置付け、勤務地、その他パラメーターとロールを組み合わせるなど、基本的な RBAC 考え方を追加機構で拡張することがよくあります。 あるアプリケーションの RBAC 拡張は、他アプリケーションと直接互換であることはめったになく、一般的データモデルは現実的ではありません。 RBAC モデルを少なくとも部分的に align する最も効率的な方法は、おそらく IDM システムの統合 power を使うことです。
基本的な incompatibility が処理されると、次の障害があります。ロール爆発 です。 必要な権限組み合わせをすべて定義するために必要なロール数は急速に増加します。 静的 RBAC モデルを使い、階層的 RBAC モデルで least-privilege 方法を実装すると、ロール数が managed ユーザー数を上回ることはかなり一般的です。
静的 RBAC モデルはアイデンティティ管理アプリケーションにはあまり適していません。 ロールの中に condition、式など、より多くのロジックを持たせて拡張する必要があります。 それでも欠点がある一方で、ロールは通常いずれにせよ必要です。 Attribute-Based アクセス制御 (ABAC) のようなより一般的ななモデルは、IDM ではさらに使いにくいものです。 そのようなモデルは、subject が object に アクセス する瞬間に権限が決定され、その操作の文脈全体が既知であるという事実に依存します。 しかし IDM システムはアカウントが作成または変更されるずっと前に判断しなければなりません。 IDM システムは認可判断そのものではなく、判断のための instruction を扱います。 ロールは IDM システムで評価されるものではないため、この定義によく合います。 ロールはむしろ、システムが理解できる別の認可概念、つまりグループ、権限、ACL、system-local グループ、さらには system-local ABAC ポリシー定義へ変換されます。 そのような system-local 概念は、ユーザーアクセスの時点で end システムによって評価されます。
アイデンティティ管理システムの導入
IDM システムの導入は通常、かなり複雑なプロジェクトです。 技術自体が複雑だからではなく、そのプロジェクトが解決する問題が複雑だからです。 IDM システムを導入する必要があるなら、統合すべきアイデンティティストアが多数あり、部分的にしか信頼できるでない情報ソースが複数あり、複雑で整理されていない業務プロセスがある可能性が非常に高いです。 IDM 導入は複雑ですが、私たちが知る限り、これらの問題に対する最良のソリューションです。
IDM システムは導入中に必ずカスタマイズされます。 それは小さなカスタマイズのことも、巨大なカスタマイズのこともありますが、何らかのカスタマイズは必ずあります。 IDM 製品間の最も重要な違いはカスタマイズへの方法です。 一部の製品は、導入中にほぼすべてを開発する必要があるプラットフォームに近いものです (例: OpenIDMv2)。 このような製品は非常に柔軟ですが、特に環境がかなり 典型的な場合は導入費用が比較的高くなることがあります。 他の製品は、多くの一般的 IDM シナリオを 標準で で実装しつつ、カスタマイズの余地も残します (例: midPoint)。 このような製品は一般に導入が容易で費用も低くなりますが、環境が通常から大きく外れている場合には適さないかもしれません。 アイデンティティ管理に関して「one size fits all」はありません。 職務に適したツールを選ぶことが重要です。
アイデンティティ管理の制約
IDM システムは本質的に複雑なデータ同期ツールです。 そのため、IDM ソリューションを design・導入する際には、いくつかの制約を念頭に置く必要があります。
-
Delay: データ propagation は im仲介 ではありません。 Delay があります。 これは、live データフィードが使われている場合の数秒から、照合が使われる場合の数日または数週間まで幅があります。
-
整合性: データのコピーが複数あり、遅延 もあるため、データ整合性は深刻な問題になり得ます。 IDM システムの 整合性機構 がそれを扱うように設計されていることを確認してください。
-
性能: IDM システムは式、プラグイン、その他専用コードを使って カスタマイズ可能 です。 これはデータ 形式化 の量を制限し、その結果 optimization も制限します。 通常、システム 柔軟性 と性能の間には トレードオフ があります。 IDM システムが柔軟であるほど、性能は悪くなります。 しかし一般に、すべての IDM システムは他のアイデンティティ管理技術 (アイデンティティリポジトリやアクセス管理など) よりかなり低い性能になります。
-
上記すべての制約を組み合わせた本当の Achilles' heel は、大量のアカウントに影響する変更です。 それは、ほぼすべてのアカウントで使われる式の変更、多くのユーザーに割り当てられているロール定義の変更などかもしれません。 このような変更は 伝播 が非常に遅く、重大な整合性リスクをもたらします。
最後に、明白でありながら十分には明白でない制約があります。
- IDM は、アプリケーションがユーザーを認証する方法、アクセスを認可する方法、監査を行う方法を変えることは できません。 IDM システムはその loop の中にいません。 アプリケーションが関連するデータを IDM システムに見える形で保存していない限り、IDM システムはユーザーがどのように認証しているかを知りません。 IDM システムは SSO を実現できません。 すべてのパスワードが同じ値に設定されるようにすることはできますが、ユーザーは毎回、何度もパスワードを入力する必要があります。 それは SSO ではありません。 IDM システムは、アプリケーション がすでに ABAC の方法を知っていない限り、アプリケーションに ABAC を行わせることはできません。 IDM システムは、アプリケーション がその情報をプロビジョニングシステムに利用可能にしない限り、3回の ログイン失敗試行 後にユーザーをアプリケーションから ロックアウト することはできません。 IDM はデータを扱っているだけです。 アプリケーション自体を変えるものではありません。
IDM システム実装
オープンソース IDM システム実装には次のものがあります。
- MidPoint: 多くのアイデンティティガバナンス機能を備えた、複雑かつ効率的な完全アイデンティティ管理システム。
- Syncope: リレーショナルデータベース上に構築されたプロビジョニングシステム。
- OpenIDM: 柔軟でプログラム可能なプロビジョニングプラットフォーム。この製品はもう 維持管理 されていません。
- wren:IDM: OpenIDM の fork。維持管理されているようですが、新機能は開発されていません。
アクセス管理
アクセス管理はユーザー認証と、部分的には認可を扱います。 アクセス管理の目的は、ユーザーが特定のシステムや機能にアクセスするときに発生するセキュリティ機構を統一することです。 アクセス管理技術は、back-end に焦点を当てるアイデンティティ管理とは対照的に、アプリケーション front-end に焦点を当てます。 アクセス管理は、ユーザーがアプリケーションへアクセスするためにどのように認証・認可されるかを変えます。
次の図は、アクセス管理導入の理論的なケースを示しています。 アクセス管理システムは、すべてのアプリケーションへのすべてのアクセスの mediator として動作します。 アクセス管理システムは、アイデンティティリポジトリに保存されたアイデンティティ情報に基づいてユーザーを認証・認可します。 すべてのアクセス check に合格した場合、ユーザーはアプリケーションへのアクセスを許可されます。
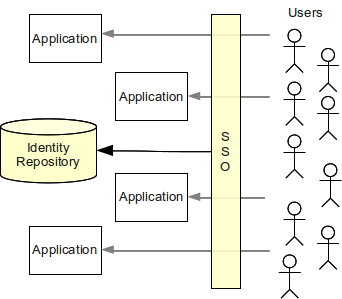
アクセス管理は、必要なすべてのアクセス制御機構をアプリケーションに提供するべきです。 ユーザーセッションデータはアクセス管理システムに保存され、アプリケーション間で共有できるため、単一 (または simplified) sign-on も容易に提供できます。 それが理論上のケースです。 しかし実務は少し異なります。
実践的なアクセス管理
アクセス管理システムは、理論上はアプリケーションを単純化するはずです。アプリケーションが独自のアクセス管理機構を実装する必要がなくなり、他のアイデンティティ管理機構も不要になるためです。 しかし実務上の問題があります。
- ほぼすべてのアプリケーションはすでに認証と認可の機構を実装しているため、一般的なケースではほとんど単純化は適用できません。 既存機構をアクセス管理に置き換えることさえかなり困難な場合があり、システムを大きく複雑にする可能性があります。
- アクセス管理システムは、単一で統合されたなアイデンティティリポジトリの存在を前提とします。 しかしリポジトリが他のアイデンティティ管理機構 (例: プロビジョニング) の結果でない限り、そのようなリポジトリはめったに存在しません。
- アクセス管理システムはアプリケーションの内部構造についてほとんど知りません。
そのため認可を判断・強制する能力は大きく制限されます。
たとえばアクセス管理システムは、ユーザーがアプリケーション
Aにアクセスできるかどうかを判断できます。 しかし、そのアプリケーションのレコード番号1234にある プロパティfooをユーザーが 変更する権限を持つかどうかは判断できません。 したがってアプリケーションは非常に多くの場合、独自の additional 認可機構を実装しなければなりません。 そのためアプリケーションは独自のユーザー記録 (アカウント) を維持管理するか、アイデンティティリポジトリへの back-end アクセスを持つ必要があります。
- アクセス管理は、ユーザーがシステムにアクセスしている場合にのみ認可サービスを提供できます。 通常はそれでよいものの、ユーザーが online でない間にユーザーの代わりに操作を実行しなければならないケースはまだかなりあります。 たとえば scheduled 作業、非同期 invocation、外部メッセージへの自動化された reaction などです。 アクセス管理技術は、これらのケースを単独では扱えません。
アクセス管理は、かなり広範な機構を含む umbrella 用語です。 一部のアクセス管理システムは認証やシングルサインオン (SSO) だけを扱い、他は認可も扱います。 Web アプリケーションに主に焦点を当てるものもあれば、クライアント machine を厳格に制御できるエンタープライズ環境でのみ機能するものもあります。 個々のアクセス管理システムはアイデンティティ管理問題に対して partial ソリューションを提供するものであり、ほぼ常に他のアイデンティティ管理技術と組み合わせる必要があります。
認証
典型的なアクセス管理システムは、アプリケーションの代わりにユーザー認証を行おうとします。 アクセス管理システムはユーザーを認証し、ユーザーセッションを作成します。 その後 接続をアプリケーションに転送 またはプロキシします。 アプリケーションは少なくとも部分的にそれを認識している必要があります。そうでなければユーザーを再度認証してしまいます。
シングルサインオン (SSO)
アクセス管理がすべてのアプリケーションに適用されると、実質的にシングルサインオン機構が作られます。 あるアプリケーションに login したユーザーは、実際にはアクセス管理システムに login しており、その結果すべてのアプリケーションに login していることになります。 SSO 機構には多くの変種と種類がありますが、最も広く使われる2つは次のとおりです。
- Web SSO は HTTP redirect を使って動作します。 ユーザーはまずアクセス管理システムに redirect され、そこで login します。 アクセス管理システムは認証情報を verify し、認可を 確認します。 すべて問題なければ、ユーザーは SSO トークンとともにアプリケーションに redirect back されます。 アプリケーションは SSO トークンを使ってユーザーがログインしていることを check できます。 Web SSO はクライアント側 (ブラウザー) のサポートを必要としません。
- True SSO。クライアントはまず SSO サーバーシステムに login します。 クライアントは認証の proof として機能するトークン (ticket) を取得します。 クライアントはアプリケーションへの各接続でチケット を提示します。 True SSO システムはクライアントに対して透過的では ありません。クライアントはプロトコルに能動的に参加します。 この方法の最もよく知られた例は、おそらく Kerberos です。
典型的な SSO システムは、全員が SSO システムを信頼するという前提で動作します。 これは典型的なエンタープライズ環境ではうまく機能し、共有 secret に基づくような効率的な SSO プロトコルを可能にします。 もちろんこれはインターネット全体には適用できないため、この種の SSO システムは「大きな」インターネットでは使われません。 代わりにフェデレーション技術が使われます (下記参照)。
エンタープライズシングルサインオン (ESSO)
エンタープライズシングルサインオン (ESSO) は名前に SSO を含んでいますが、他の SSO 機構との共通点はほとんどありません。 ESSO は実際には、ログインダイアログが現れるのを静かに待つ非常に単純なエージェントにすぎません。 Dialog が現れると、ESSO エージェントはユーザー名とパスワードを入力し、その dialog を送信します。 ユーザーは通常これに気づかないため、自分はすでにログイン済みしていたと考えます。 これにより SSO の illusion が生まれます。
ESSO はすべての workstation にエージェントを必要とするため、厳格に制御された環境でしか適用できません。 エージェントがユーザーのすべての (平文) パスワードを知る必要があるため、セキュリティ脆弱性にもなり得ます。 一部の ESSO システムは、login の直前または直後にパスワードを変更することで ワンタイムパスワード機構を シミュレートし、この問題を克服しようとします。 しかしこれはパスワード管理の悪夢を生み、かなり同質な環境でしか実務的に現実的ではありません。 さらに、エージェントが任意のアプリケーションについて current パスワードを知っているか取得できなければならないという事実は変わりません。
認可
アクセス管理システムは通常、少なくとも何らかの認可を行います。
しかしアクセス管理システムが認可サービスを提供する能力は大きく制限されています。
アクセス管理システムは誰がシステムにアクセスしているか (subject) は知っていますが、操作 については非常に粗い考え方しかなく、その操作が影響する object についてはほとんど何も知りません。
しかし認可 triple の3つすべてを知ることは、良い認可判断の不可欠要件です。
したがってアクセス管理システムは、「システム Foo への (任意の) アクセスを許可する」、「パターン /private/* に 一致する URL への HTTP POST 操作を許可する」といった粗い認可判断しかできません。
それより細かな認可が必要な場合、それは通常アプリケーション自身が行わなければなりません。 アプリケーションは 操作 と object に関するすべての詳細を知っていますが、subject に関する詳細は持っていません。 したがってアプリケーションは、認証済みユーザーの詳細をアクセス管理システムから取得できなければなりません。
フェデレーション
簡単に言えば、アイデンティティ フェデレーション はインターネット越しの SSO です。 SSO は通常、アイデンティティリポジトリとアプリケーションの両方が単一組織内にあることを前提とします。 したがって信頼は 暗黙的であり、プロトコルは 独自である場合があります。 フェデレーション はさらに一歩進み、そのような前提を置きません。 そのため communicating party の explicit 信頼と strong 認証が必要です。 またフェデレーションプロトコルは open でなければならず、機構はインターネット利用向けに設計されていなければなりません (堅牢でスケーラブルなど)。 しかしそれ以外では、SSO とフェデレーションの技術的な原則はほぼ同じです。
単純フェデレーションシナリオを次の図に示します。 各 color はインターネット越しに接続された異なる組織を意味します。 そのうち1つの組織がアイデンティティ Provider です。 この組織はユーザーを認証するために使われるアイデンティティリポジトリを維持管理します。 ユーザーがログインすると、アイデンティティ Provider はユーザーに assertion (フェデレーショントークン) を課題します。 この assertion は認証の proof として使われます。 それは他の組織 (サービス Provider) に提示でき、サービス Provider はユーザーを受け入れます。 Assertion はかなり rich にできます。たとえばユーザー属性、権限、ロール、認可判断なども含められます。 これはサービス Provider による further 認可に使えます。
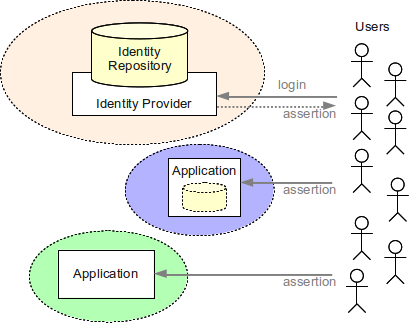
おそらく最も広く使われているフェデレーションプロトコルは SAML です。 Cross-Domain SSO (CDSSO) と呼ばれる機構もあり、複数のインターネット domain にまたがるためフェデレーションと同一に見えるかもしれません。 しかし CDSSO は主に、通常の SSO cookie をインターネット domain 間に 伝播 する workaround として使われるもので、フェデレーションの他の機能 (開放性、信頼、堅牢性、拡張性) を持ちません。
アプリケーション側
アクセス管理は front-end アイデンティティ統合技術です。 つまり、ユーザーがアプリケーションと やり取りする方法を変えます。 通常変更される唯一の側面はユーザーがアプリケーションに認証する方法ですが、それでも変更は必要です。 アプリケーションまたはそれを支えるフレームワークは、アクセス管理ソリューションをサポートする必要があります。 最も intrusive でないケースは、フレームワーク (例: Java EE アプリケーションサーバー) を設定するか、専用のエージェントを install することです。 この方法は認証と coarse-grain 認可についてはアプリケーションに対してほぼ透過的にできます。 しかしアクセス管理をより tightly に統合する必要がある場合、アプリケーションの修正はほぼ避けられません。
アクセス管理サポートを追加するためにアプリケーションを 変更する必要は、遅かれ早かれ発生します。 アクセス管理システムは通常、その作業を容易にする API や library を提供しますが、それでも本格的な作業です。 細粒度の認可が必要な場合、この必要性は特に早く訪れます。 アプリケーションとアクセス管理システムのセキュリティモデルがうまく align していない場合、さらに複雑になります。
アプリケーションを 変更するという要件により、アクセス管理はある程度 intrusive な技術になります。 そして導入費用もかなり高くなります。
アクセス管理と IDM
アクセス管理技術は通常、単一、一貫した、信頼できるアイデンティティリポジトリを必要とします。 この要件は、シングルサインオンソリューションを導入する場合に特に重要です。 しかし、そのようなリポジトリをどうやって得るのでしょうか。 ユーザー名はアプリケーション間で同期されていないことがよくあります。 したがって、どれか1つのアプリケーションのアイデンティティリポジトリを採用してもうまくいかないのが普通です。 これが full-scale アクセス管理導入が通常失敗する理由の1つです。
アクセス管理技術はアプリケーションのローカル状態をほとんど気にしません。 したがってアプリケーションがローカルユーザー記録を必要とする場合、アプリケーションはユーザーが最初にシステムにアクセスするときに on demand でそれを作成しなければなりません。 これは特にフェデレーション導入でよくあるケースです。 つまりユーザーは on demand で自動的に プロビジョニング されます。 しかしユーザーは決して デプロビジョニングed されません。 アイデンティティ Provider リポジトリでユーザーアカウントが削除されると、それは単に消えます。 サービス Provider には通知されません。 ユーザーデータはサービス Provider 側に無期限に残ります。 これは、特に additional (ローカル) 認証や認証情報 reset が設定されていた場合、データ exposure の潜在的なリスクです。 いずれにせよリソースを無駄にし、たとえば ユーザー単位のサービス価格モデルが使われている場合には不要な費用を引き起こす可能性があります。
IDM システムは通常、アクセス管理導入の前提条件です。 IDM システムには、アクセス管理システムが使える統合されたアイデンティティリポジトリを作成する能力と 柔軟性 があります。 複数のアイデンティティリポジトリを同期された状態に保つことにも適しています。 したがってデプロビジョニング問題を効率的に解決できます。 アイデンティティ管理 側面 を欠くアクセス管理ソリューションの 大規模導入は、ほとんど成功しません。
アクセス管理実装
アクセス管理 カテゴリ に該当し得る実装は多数あります。 いくつか挙げると次のとおりです。
- Keycloak
- GLUU
- CAS は SSO プロトコルであり実装でもあります。
- Shibboleth は SAML-based プロトコルであり、主に academic アプリケーションで使われる実装です。
- OpenAM は Java のアクセスマネージャー実装です。 Domain cookie とその他のプロトコルを使います。 OpenSSO プロジェクトの継続です。 このプロジェクトはもう 維持管理 されていません。
- wren:AM: OpenAM の fork。
組み合わせる
アイデンティティ管理技術のどれも、それ単独でソリューションを提供するものではありません。 最小かつ最も単純なアイデンティティ管理プロジェクトを除けば、実務的なソリューションには複数技術の組み合わせが必要です。
システム
プロジェクトの鍵は、何を統合する必要があるかを知ることです。 アイデンティティ管理に関しては、システムにはいくつかの種類があります。
| 説明 | ソリューション | |
|---|---|---|
| 単純 stateless システム | 自身のアイデンティティ情報をまったく維持管理しません。 このようなシステムはユーザーアイデンティティを知る必要すらない場合があります。 単純な許可 all/拒否 all の認可判断だけで十分です。 |
アクセス管理システムだけで統合は trivial です。 システムがアイデンティティデータを必要とする場合、最も簡単な方法は cookie や HTTP パラメーターに inject することです。 |
| アイデンティティリポジトリ統合を持つ状態保持システム | アイデンティティ情報へのアクセスが必要ですが、共有アイデンティティリポジトリ (例: LDAP) を使えます。 共有アイデンティティリポジトリの内容に基づく複雑認可判断をサポートする場合があります (例: アカウント属性の評価)。 |
共有アイデンティティリポジトリ (例: ディレクトリサービス) に接続します。 可能であれば認証をアクセス管理に置き換えます。 システムが通常必要とする唯一のものはユーザー識別子 (例: ユーザー名) であり、これは通常プラットフォーム (例: Java EE セキュリティサブシステム) によって伝達できます。 その後システムはプロファイルの残りをアイデンティティリポジトリから直接取得できます。 |
| 状態を持つシステム that 必要とs ローカルデータ | 性能理由 (例: レポートのためのデータ join 能力)、共有リポジトリサポートの欠如、データモデル incompatibility などにより、ユーザー記録 (アカウント) の独自コピーを維持管理する必要があります。 |
ローカルデータを共有アイデンティティリポジトリと同期します。 通常、最良の方法は IDM システムの導入です。 アクセス管理システムと統合できる場合もあります。 |
| レガシーシステム | 共有アイデンティティリポジトリと統合できず、独自のローカルアカウントを保持します。 アクセス管理と統合できず、ハードコード 認証を実装しています。 まだ動いているだけでも幸運です。 |
選択肢は多くありません。 おそらく最善は、そのアカウント記録を共有アイデンティティリポジトリと同期することです。 ここでは IDM システムが本当に最良のソリューションです。 認証の 都合 についてできる唯一のことは、プロビジョニング機構を使って共有アイデンティティリポジトリからこのシステムにパスワードを同期することです。 |
さらに、データのソースとなるシステムもあります。 典型的なのは人事(HR)システムで、通常従業員データの信頼できるソースです。 次に CRM があり、顧客とパートナーデータのソースです。 そして通常、請負業者、independent エージェント、volunteer、その他信頼できるソースを持たない多くのユーザー種類も存在します。 ソースが従業員記録の存在と status について信頼できるであっても、メールアドレスや組織構造内でのユーザーの 場所ment については完全に信頼できるではない場合があります。 組織が大きく、柔軟で、business-oriented であるほど、結果として生じる状況はより複雑になります。 このような状況を扱える実務上ほぼ唯一のソリューションは IDM システムです。
解決策
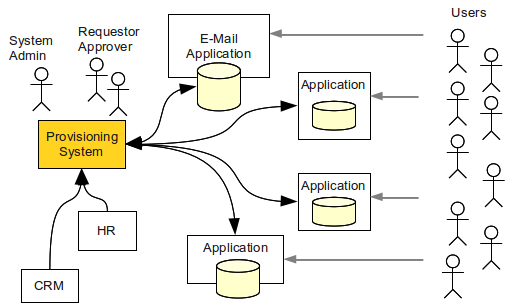
実務的な IAM ソリューションには、少なくともアイデンティティリポジトリ、アイデンティティ管理、アクセス管理機構の組み合わせが必要です。 これらの技術は、次の図に示すように互いを補完します。
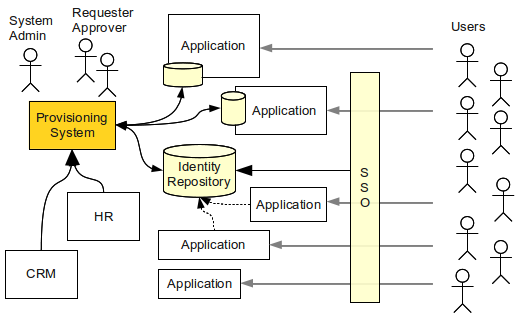
IDM システム は、組織全体でアカウントとユーザー記録を同期します。 HR や CRM システムなど、さまざまなデータソースからデータを pull し、そのデータの統合ビューを作成します。 レガシーシステムと状態を持つシステムのデータベースを sync された状態に保ちます。 しかし最も重要な責任は、共有 アイデンティティリポジトリ を維持管理することです。 アイデンティティリポジトリは、それを利用できるアプリケーションによって使われます。 またアクセス管理システムによって、一貫した信頼できるユーザーデータベースとしても使われます。
プロジェクト
アイデンティティ管理プロジェクトは頻繁に失敗します。 典型的なアイデンティティ管理プロジェクトは、大きな 全か無かの waterfall-like プロジェクトです。 それはプロジェクトではなく、失敗と巨大な費用の無駄の計画です。 理由は多数ありますが、おそらく最も重要なのは知識の不足です。
- アイデンティティ管理技術は複雑です。 IDM エンジニアは1年では訓練できません。 必要な経験を得るには少なくとも5年かかります。
- 環境は複雑です。 顧客は、自分がシステムのすべてを知っていると主張し、1000ページの分析でその主張を支えるかもしれません。 しかし現実はかなり異なります。 Surprise は必ずあります。
- 要件は複雑です。 要件はプロジェクトの初期に見えるほど clear ではありません。
- 作業は hard です。 アイデンティティ管理プロジェクトは、見かけよりはるかに多くの労力を必要とします。 経験豊富な エンジニア でさえ、total 労力を underestimate しがちです。
Waterfall-like プロジェクトは機能しません。 プロジェクト目的を満たすことには成功するかもしれませんが、顧客に expected 価値をもたらしません。
プロジェクトを小さな手順に分割し、イテレーション と increment で進めてください。 各手順で価値をもたらしてください。 効率的に進められる範囲までだけ進めてください。 一部の作業は、人間が手作業で行うのが今でも最も効率的です。 基本構造を設定し、必要に応じて各手順で改善してください。 プロジェクトの初期に高い ライセンス 費用を支払うことは避けてください。それは価値を効果的に消し、TCO を台無しにします。 ベンダーと交渉するか、単に open-source ソフトウェアを使ってください。
アイデンティティ管理技術実装の通常の順序は次のとおりです。
-
IDM システム。パスワードリセット 手順 を改善し、ユーザー管理を高速化し、監査をより効率的にし、多くの 運用費用を削減します。 IDM システムを導入する incentive は主に economic ですが、技術的な incentive も大きくあります。IDM システムはデータを clean up します。 データは次の手順に向けて準備されます。
-
アイデンティティリポジトリ。アプリケーション間で共有され、従業員、顧客、請負業者、パートナーなどの記録に統合ビューを提供します。 IDM システムがデータを populate し、最も重要なこととして維持管理します。
-
アクセス管理。リポジトリを使って SSO と、統合可能なサービス向けのある程度集中化されたな粗い認可を提供します。
順序は単純な IDM、リポジトリ、AM ではありません。 これは iterative です。 したがって、より次のように見えます。
-
基本プロビジョニング: システムを IDM システムに接続します。 すべてを手作業で行いますが、単一箇所 から行います。 これにより ヘルプデスク の時間が大きく節約されます (単一箇所 からのパスワードリセット、またはセルフサービスパスワードリセット)。 監査をサポートするレポートもかなり容易になります。
-
基本リポジトリ: IDM システムから中央アイデンティティリポジトリにデータを公開します。 まだカスタマイズせず、標準スキーマを採用します。 単純アプリケーションをリポジトリに接続します (例: LDAP 対応 Web アプリケーション)。
-
基本アクセス: リポジトリデータを使って単純 Web SSO システムを導入します。
-
改善されたアイデンティティ管理: 一部の IDM 作業を 自動化します (例: "新規採用" プロセス)。 基本ロールを作成します。 ロールとその他権限の申請と承認プロセスを設定します。
-
改善されたリポジトリ: より多くの必要データを公開するためにスキーマを拡張します。 アプリケーションを改善し、それらのデータをより良い認可に使えるようにします。
-
改善されたアクセス: SSO を他アプリケーションに拡張します。 より細粒度な認可のために一部アプリケーションを 修正します。
-
...
一部の手順は reorder されたり、skip されたりする場合があります。 たとえば、すでに solid なリポジトリ (従業員が populate された Active Directory インスタンス など) がある場合、最初の「基本プロビジョニング」手順は skip されるかもしれません。 しかしその作業は戻ってきます。 アイデンティティ管理の次の イテレーション はより困難になります (たとえば顧客とパートナーもリポジトリに入れる必要がある場合)。 労力は多少 最適化 されるかもしれませんが、全体的なプロジェクト状態は大きく変わりません。
ヒント
- 可能であれば、システムを共有アイデンティティリポジトリに統合してください。特に標準プロトコル (例: LDAP) でアクセスできる場合はそうです。 これが最も費用効率的な方法です。
- ほとんどのアプリケーションに合うスキーマを作成してください。
標準スキーマ (例: LDAP
inetOrgPerson) を ベースラインとして使ってください。 ほぼすべての導入は、何らかのスキーマ拡張とカスタマイズを必要とします。
- スキーマを 過度に複雑化しないでください。 どれだけ頑張っても、スキーマがすべてのアプリケーションに同時に合うことはありません。 特殊なケースと複雑データモデルは IDM システムで扱う方が適しています。
- セキュリティ要件や purchasing ルールなどによって、すべてのシステムに単一ディレクトリサーバー方法を 強制 する魅力に抵抗してください。 システムが適切なプロトコル (例: LDAP) をサポートし、スキーマがそのシステムによく合う場合は、中央リポジトリに接続してください。 そうでない場合は、強制しないでください。 一般的共有アイデンティティスキーマは必然的に compromise です。 すべての人に compromise の使用を強制すると、価値の少ない mediocre なソリューションが生まれます。 そして深刻な問題を作ります。 個々のアプリケーションは、共有スキーマにないデータ (例: 細粒度の権限、勤務地、アクセス zone など) を保存するために、依然として独自のアカウントを維持管理する必要があります。 ポリシーや purchasing 要件という文書 screen の背後に状態を隠しただけでは、extra 状態による問題は避けられません。 状態はそこに残ります。 アプリケーションはポリシーに準拠するために、自身のアカウントと中央リポジトリを同期しようとするだけです。 しかしこれは実質的に、各アプリケーションごとに専用の IDM システムを作ることになります。 このような同期をうまく行うことは非常に困難であり、ほとんどの場合うまく行われません。 そのため継続的な 運用上の問題を生み、維持管理の悪夢になります。 最終的には、同じ作業が各システムで何度も繰り返されるため、非常に高価になります。 代わりに中央IDM システムを使ってください。 その方が安く、維持管理が容易で、データを制御できます。
- 要件に priority を付けてください。 これはソフトウェアであり、ほぼ何でも可能です。 しかし、時間がかかりすぎ、費用が高すぎるものもあります。 技術が効率的に解決できる問題を解決するために技術を使ってください。 技術は進化します。 今日効率的に解決できないものが、来年には簡単な作業になるかもしれません。
- 80:20 を考えてください。 20% の作業で 80% の結果を達成すべきです。 すべてのアイデンティティ管理作業の 100% 自動化は可能かもしれませんが、非常に高価になる可能性があります。 技術的な excellence ではなく economic 効率 を目指してください。 20% の費用で達成できる 80% 自動化こそ、まさに必要なものかもしれません。
- ロール (RBAC) を 過度に複雑化しないでください。 ロール爆発 は一般的問題であり、RBAC プログラムにとって明らかな行き止まり です。
- Home-brew ソリューションを検討してください。 既存製品を reinvent する意味はないため、それらを使ってください。 相互補完的な既存製品をいくつか取り、カスタマイズして自分で組み合わせてみてください。 この DIY 方法は、特に イテレーション で実装される場合、驚くほど良い結果を提供します。 要件をあなた以上に知っている人はいません。 IDM expertise の不足は、製品ベンダー、開発者、パートナーからの advice によってある程度補えるかもしれません。
- ソリューションを選択または実装するときは、整合性機構 を必ず考慮してください。 遠くから見ると実装詳細に見えるかもしれませんが、この小さな詳細がプロジェクト全体を台無しにする可能性があります。 そして、これを完全に誤っている製品、機構、API、プロトコルは多すぎます。
結論
アイデンティティ管理は多くの技術の混合体であり、その混合は治癒薬にも致命的な薬にもなり得ます。 最良の方法は 現実的 であることのように見えます。大きな期待を避け、改善が必要で、かつ 経済的・技術的に現実的な場所でシステムを改善することです。 アイデンティティ管理は magic ではなく、技術にすぎません。 しかもかなり若い技術です。
この文書は、さまざまなアイデンティティ管理機構、手法、その組み合わせを説明しています。 また行き止まり への警告を行い、神話を debunk しています。 しかしアイデンティティ管理実装への単一の適切な方法は提供しません。そのようなものは存在しないためです。 環境はそれぞれ異なり、要件は変わり、リソースは limited です。 すべての導入は異なります。 すべてのソリューションは異なります。