IDM 整合性
この記事は https://docs.evolveum.com/iam/iga/idm-consistency/ の翻訳です。
整合性問題
現在のシステムの大半は、read-compute-write 原則で動作します。
-
Read: 価値をデータストアからローカルメモリに読み込む
-
Compute: ローカルメモリ内で価値を変更する
-
Write: 新しい価値をデータストアに書き戻す
この方法は次の図で示されています。
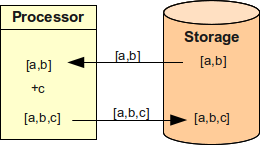
ユーザーを新しいグループ c に割り当てたいとします。
ユーザーはすでにグループ a と b を持っています。
そのため processor は価値 [a,b] を読み取り、価値 c を追加し、新しい価値 [a,b,c] を書き戻します。
これはうまく機能します。
ほとんどの場合は。
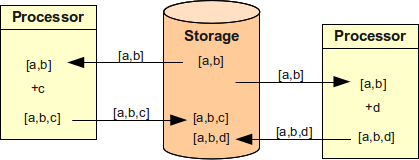
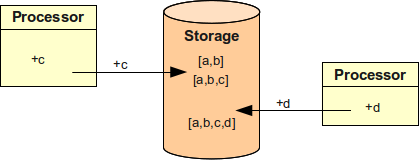
問題は、複数の processor がデータストアを扱う場合です。
その状況を次の図に示します。
2つの processor がそれぞれグループ c と d を同時に追加しようとしています。
結果の価値は正しくありません。
一方の操作が実質的に消えてしまいました。
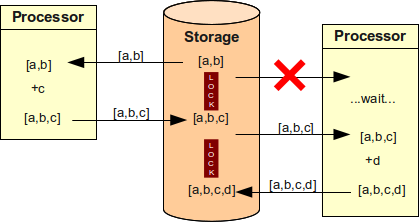
Software エンジニアはこの問題を理解しており、これを回避するいくつかの方法を設計してきました。 最も一般的な方法は ロックing で、次の図に示されています。 これは前の図と同じ状況を表していますが、今回は最初の read の後に価値が ロック されます。 2つ目の processor はそれを read できず、最初の processor が操作を終えるまで待たなければなりません。 システムの効率は低下しますが、結果は正しくなります。 この方法の variation である 楽観的ロック は、MVCC の一部であり、ロック の軽量版を利用して読み取り専用操作は ロック を待たずに進められるようにします。 それでも、write 操作に関しては非常によく似た性質を持ちます。 これは tightly coupled システムではうまく機能し、現在の "ベストプラクティス" です。
しかし、この方法にはいくつかの重大な欠点があります。 システムが 疎結合 である場合、外部クライアントがデータを ロックアウト することでシステムの操作に影響を与えることができます。 すると、ビジネスクリティカルなではないクライアントでさえ ビジネスクリティカルなシステムに影響を与えられます。 これは良いエラー処理 や 楽観的ロック への切り替えで改善できますが、システムはより複雑になります。 Optimistic ロックing は修正 rate が高いシステムにも適していません。 しかし ロックing 方法の本当の Achilles heel は、承認のような長時間実行されるプロセスです。
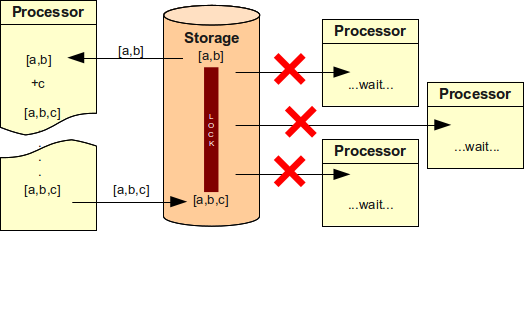
ユーザーへのグループ割り当てがセキュリティ担当者 の承認を必要とすると仮定します。 このケースは次の図に示されています。 Processor はユーザーにグループを追加し、承認を求めます。 しかしセキュリティ担当者は現在休暇中であるため、申請は送信され、差し戻され、照会され、失われ、発見され、公開照会 にかけられ、エスカレーションされ、委任され、最終的に承認されます。 他のすべての processor は、この単純な業務プロセスが終わるまで待たなければなりません。 それにはかなり時間がかかるかもしれません。
Optimistic ロックing を使っても、この状況は大きく改善しません。 Optimistic ロックing が使われる場合、他の processor は待たずに自分の操作を実行します。 しかし最初の申請が最終的に承認されたとき、データストアの状態はその間に変化しているため、その申請をデータストアに反映できません。 したがって業務プロセス全体を最初からやり直す必要があります。
この "absolute" 変更モデルを IDM システムで実用的でなくする課題は他にもあります。 たとえばリソースとの communication が失敗した場合、ユーザーをグループに追加するような操作は queue に入れられるべきです。 しかしシステムが数日間アクセス不能になることがあり、再び online になったときにはローカル変更があるかもしれません。 Queued 操作はそのような変更を over書き込むか、失敗する可能性があります。 システム failure 後の restore などによりシステム状態が rollback された場合にも同様の問題が発生します。 完全な新しい状態を強制すると、システム integrity に影響する可能性があります。
この種の課題はかなり以前から知られていました。 2000年、Brewer 教授は分散したシステムの整合性には本質的な限界があると推測しました。これは "Brewer's conjecture" として知られるようになりました。 これは2年後に正式に証明され、現在は CAP theorem として知られています。 CAP theorem の consequence は、実用的な分散したシステムで可用性を犠牲にせずに strong 整合性を得ることはできない、というものです。
Read-compute-write モデルに基づく IDM システムは、根本的にあらゆる 運用上の問題に悩まされる運命にあります。
結果整合性
唯一の実用的なソリューションは、システムの整合性を弱め、可用性と reasonable 整合性の両方を得ることです。 整合性は依然として重要ですが、データがあらゆる瞬間に一貫していることは要求しません。 要求するのは、遅かれ早かれデータが一貫した状態に到達することです。 これは現在 eventual 整合性 として知られています。 ただし、この方法は LDAP replication 機構や他のシステムで、ほぼ20年にわたって使われてきました。
結果整合性を 指針として採用すると、合理的な トレードオフ が得られます。つまり、データについてほぼ正しい情報を提供する可用システムを持てます。 まれに誤った、つまり stale なデータがある場合でも、状況はいずれ正されます。 少し待てばよいだけです。 これはアイデンティティ管理システムを含む大多数の統合システムにとって十分です。
結果整合性の欠点は、ロック が実質的に役に立たないことです。 あるデータ片 を取得し、他の全員も同じ価値を得ると確信できる実用的な方法はありません。 したがって、少なくとも多少の可用性を犠牲にするか、重要なシステム failure のリスクを負わない限り、データを ロック することはできません。Optimistic ロックing でさえ同じです。 そのため、eventually 一貫したシステムがうまく機能するように、別の方法を取る必要があります。
相対変更
基本的な考え方は、読み取り・計算・書き込みサイクル を取り除くか、少なくとも最小限に減らすことです。 その鍵は、古い価値に依存せずに新しい価値をどう構成するかを記述するデータ構造、すなわち relative change の導入です。 たとえば relative 変更は、既存価値に言及せず、追加または削除すべき価値を記述できます。 このような変更は、データを ロック する必要なく元のデータに適用できます。 この relative 変更を delta と呼びます。
相対変更を扱う単純なケースを次の図に示します。 これは前の図と似たシナリオを示しています。 しかしこのケースでは、processor は既存価値を読み取り、新しい結果を計算し、それを書き戻しているわけではありません。 Processor は単に操作をデータストアに渡します。 データストアは 実データを使って操作を実行します。 データストアは実際には短時間データを ロック するかもしれませんが、その ロックing は processor からは見えません。 Lock は短時間だけなので、保存場所自体の自然な性能 limit を超える大きな 枯渇 も引き起こしません。
ただし、いくつかの制約があります。
データ価値の ordering は重要であってはなりません。価値は unordered でなければなりません。
Eventually 一貫したシステムは操作の ordering を保証できないため、操作はデータストアに任意の順序で "land" する可能性があります。
価値の ordering が重要な場合、操作の結果は予測不能になりすぎて役に立たない可能性があります。
データを unordered にすることで、状況は大きく改善します。
このケースでは、価値 c が d より前に追加されたか、その逆かは重要ではありません。結果は同じです。
しかし、それで 順序の課題が完全に解決するわけではありません。
たとえば、ある価値に対する add 操作と delete 操作がデータストアでどの順に実行されたかは依然として重要です。
したがって conflict や誤った結果はまだ発生し得ます。
ただし、そのような状況は非常にまれであり、実務上対処することは難しくありません。たとえば操作 timestamping、手作業 intervention、重要なデータへの strongly 一貫した保存場所の利用などです。
もう1つの課題は、データ computation の方法を変更しなければならないことです。
Computation の結果は新しい価値集合ではなく、新しい価値集合への変更でなければなりません。
たとえば [a,b,c] ではなく、computation は +c を生成しなければなりません。
この方法を最初から念頭に置いてシステムが設計されていない限り、これは実装がかなり困難です。
照合
相対変更は 疎結合 システムではうまく機能しますが、この方法では扱えない状況もまだあります。 そのような状況はかなりまれですが、システムはそれを扱い、そこから recover できなければなりません。 照合プロセスは、すべての eventual 不整合を捕捉し、システムを信頼できるに一貫した状態へ戻すために設計された機構です。 照合は、データがどう あるべきか という absolute 状態と、実際にどう あるか を比較します。 照合はかなり遅く、負荷の高いプロセスです。 しかし不整合は頻繁に起こるわけではないため、照合も頻繁に実行する必要はありません。
照合にはもう1つの効果があります。報告されなかった変更、または通知メッセージが失われた変更を検出できます。 したがって照合は、いずれにせよ任意の IDM 導入の一部であるべきです。 相対変更の誤適用によって生じる不整合の追加確認 は、ほとんど無視できる負担です。