アイデンティティガバナンスおよび管理
この記事は https://docs.evolveum.com/iam/iga/iga-introduction/ の翻訳です。
はじめに
アイデンティティガバナンスおよび管理 (IGA) は、アイデンティティおよびアクセス管理 (IAM) の分野であり、アイデンティティ関連情報の管理とガバナンスを扱います。 簡単に言えば、IGA はアイデンティティ情報の維持管理に関するすべての詳細を扱います。低レベル技術的な詳細から 高レベルの業務ポリシーまでが範囲です。
低レベルでは、IGA システムはユーザーアカウントやプロファイルなどの デジタルアイデンティティ情報をストア、同期、管理します。 IGA 機構は低レベルアイデンティティ情報を 組み合わせ、多くの個々の断片から構成されたデジタルアイデンティティの統合ビューを作ります。 ポリシー、アクセス制御モデル、業務ルールは統合されたアイデンティティの上に 適用され、整合性とセキュリティを維持します。
アイデンティティ
アイデンティティガバナンスおよび管理 (IGA) を深く掘り下げる前に、アイデンティティ について議論する必要があります。 アイデンティティ は非常に 抽象的な概念です。 私たちは現実世界の アイデンティティ について直感的な理解 を持っています。 しかし、その直感的な理解 をサイバースペースに適用するのは簡単ではないことが分かります。 サイバースペースにおける アイデンティティ には多くの定義があり、多くの同義語や代替用語もあります。デジタルアイデンティティ、ネットワークアイデンティティ、仮想エンティティ、ユーザーアカウント、ユーザープロファイルなどです。それぞれに 正確さと意味合いの違い があります。 さらに悪いことに、これらの用語は identifier や personally identifiable 情報 (PII) などの 関連用語と頻繁に 混同されます。 ここでは、デジタル側面が文脈から明らかな場合、"デジタルアイデンティティ" または単に "アイデンティティ" という用語を使います。
さらに、アイデンティティは本質的に 主観的です。観点によって異なる形式を取ります。 たとえば 私的利用と業務利用の異なるアイデンティティ側面 である persona が存在することがよくあります。 アイデンティティは 関係 を形成し、グループや組織に参加し、時間とともに進化し、アイデンティティの 側面は隠され、公開され、検証され、第三者に証明され、停止され、再開され、アーカイブされ、最後には消去されることがあります。 全体として、アイデンティティは複雑です。 その複雑性に対処することが IGA 技術の主な責任です。
IGA の観点では、"デジタルアイデンティティ" は人物、アプリケーション、デバイスなどの エンティティの特徴を記述する情報集合です。 デジタルアイデンティティはデータベース記録、ディレクトリエントリ、ユーザーアカウント、スプレッドシートの行 など、多くの形式を取ります。 アイデンティティはしばしば attribute の集合として見られます。 これはデジタルアイデンティティのモデルを単純化するための一般的な慣習 です。 しかしアイデンティティには、他のアイデンティティやオブジェクトへの 関係、行動特性、その他属性の形式では 表現しにくい 側面 も含まれます。 デジタルアイデンティティの特定の形式にかかわらず、IGA プラットフォームはデジタルアイデンティティを特定のエンティティを記述するデータの集合 として見ます。
アイデンティティスプロール
デジタルアイデンティティは多くの状態と形式を取ります。
アイデンティティを属性集合として 単純化しても、さまざまなアイデンティティ形式を統合ビューに揃える助けにはあまりなりません。
多くのシステムは aanderson のような 短くユーザーフレンドリーなユーザー名を使ってユーザーを特定します。
他のシステムは alice.anderson@example.com のようなメールアドレスを使います。
人事システムは 035431217 のような従業員番号をよく使います。
一部のシステムは UUID (74ddc2f7-5c2b-4f80-ab15-cb757d21ae86) のような 疑似ランダムでグローバルに一意な 識別子を使い、バイナリ識別子にまで頼ることもあります。
LDAP 識別名 (uid=aanderson,ou=People,dc=example,dc=com) のような構造化された識別子形式、さまざまな内部形式とレガシー形式があります。
統合されたリソース名前 (URN)、locator (URL)、識別子 (URI) もありますが、結局それほど統合されているわけではありません。
複数識別子の組み合わせを使うシステムもあります。
これは混沌です。そして私たちはまだ識別子だけについて話しています。
デジタルアイデンティティの断片を一貫した統合ビューに統合することは簡単な作業ではありません。 TODO: 人物の名前のような単純なものでも、単一文字列、構造化された名前、ミドルネーム、敬称、国ごとの表記揺れ、文字集合、日本語とラテン文字表記 などの問題があります。
アイデンティティの統合ビュー
TODO: 一般的データモデル、スキーマ、同期。 アカウントリンク。 TODO: スター型トポロジ。 TODO: 可視性。IGA プラットフォームは可視性を提供しなければならず、これが 出発点 です。
アイデンティティ管理
TODO: アイデンティティ スプロール を管理する。 TODO: 棚卸し、孤立したアカウント。 TODO: アクセス制御、アクセス制御モデル、エンタイトルメント。 TODO: 衛生、態勢。
アイデンティティガバナンス
TODO: ポリシー、ルール。 TODO: プロセス、アクセス申請、認定。 TODO: ポリシーの維持管理、見直し、責任。 TODO: コンプライアンス。 TODO: レジリエンス。 IGA システムはポリシーを評価し、データが準拠であることを保証し、ポリシー違反に対処する責任を持ちます。
アイデンティティおよびアクセス管理
TODO: IGA は IAM の非常に広い領域をカバーしますが、すべてを cover するわけではありません。 IGA は認証、セキュリティトークン、ユーザーがアプリケーションにアクセスする方法には関与しません。 それはアクセス管理 (AM) の懸念です。 IGA は認可にも直接関与しませんが、認可に影響するエンタイトルメントの管理は IGA の一部です。
古い内容
用語
TODO: IGA は、アイデンティティ管理、アイデンティティガバナンス、コンプライアンス管理、アイデンティティベースリスク管理、その他アイデンティティの管理に関連する 側面を包含する包括的な用語と見なされることがよくあります。
アイデンティティ専門家は、しばしば マーケティング上の必要性に動機づけられ、新しい名前を考案し、それを使って同じものを説明することを好みます。 そのため、多くの 重複した類似用語が使われています。 アイデンティティ管理 (IDM) は低レベル部分、つまり技術を説明するために使われ、アイデンティティガバナンス は 高レベル部分、つまり業務を説明するために使われます。 しかし 境界は非常に曖昧 であり、多くの IDM システムはガバナンス機能を提供し、多くのガバナンスシステムは低レベル機能を提供します。 ガバナンス、リスク管理、コンプライアンス (GRC) は、過去に高レベル アイデンティティガバナンス機能を表すために主に使われていた用語で、後に単に アイデンティティガバナンス として知られるようになりました。 アイデンティティセキュリティ は、IGA 機能を おおよそカバー する マーケティング用語です。
全体として、用語は非常に流動的 です。 ベンダーは独自の用語を使い、多義的または紛らわしい な用語を選ぶことがよくあります。 Marketing 用語は文書が適応するより速く 考案され、状況をかなり 混乱させます。 私たちは用語を理解可能 に保ちながら、できるだけ正確に用語を まとめようとしました。 多くの用語が 多義的で曖昧 であるにもかかわらず、可能な場合は 定着した業界用語に従うことを選びました。 しかし用語を 再発明して混乱を高めるしたくはありませんでした。 必要に応じて本文中で 曖昧さ を指摘します。 迷った場合は 用語集 を参照してください。
アーキテクチャ
アイデンティティガバナンスおよび管理 (IGA) システムは IT インフラストラクチャ層 の一部です。 アプリケーションとアイデンティティデータストア内のアイデンティティ関連情報を管理・監視する不可欠サービスを提供します。 IGA システムはアイデンティティデータを統制し、それが最新で一貫していることを確認し、ポリシーを適用し、アイデンティティ関連セキュリティ課題を検出し、アイデンティティ関連リスクを評価し、不可欠可視性と分析機能を提供します。
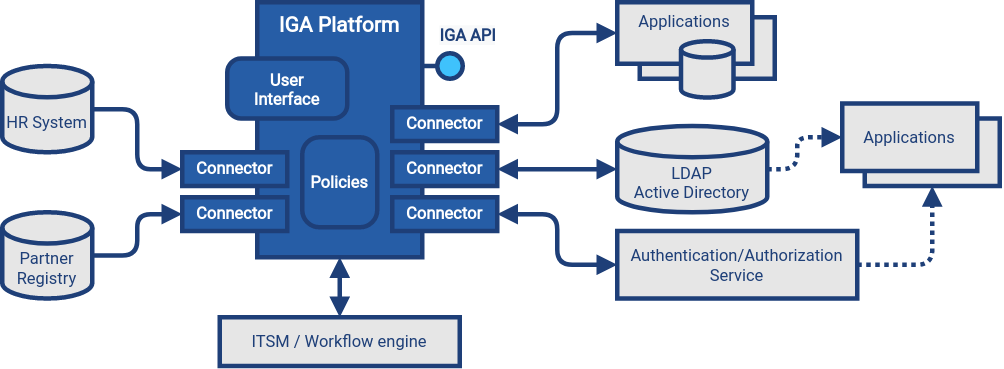
IGA プラットフォームには2つの主な機能があり、それが2つの主なデータフロー につながります。
-
アイデンティティ管理、つまりアイデンティティ管理は、人事(HR)システムからのデータなど信頼できるデータに基づくユーザーアカウントとエンタイトルメントの管理に重点を置きます。 この機能を実現するために、IGA プラットフォームはソースシステム、たとえば HR からデータを読み取り、それをプロセスし、対象システム、たとえば LDAP、Active Directory、アプリケーションにデータを書き込みなければなりません。
-
アイデンティティガバナンス は、アイデンティティデータへのポリシーアプリケーション、アイデンティティ関連プロセスの推進、アイデンティティとエンタイトルメント情報の収集と分析、リスク評価、ポリシー改善提案に重点を置きます。 この機能を実現するために、IGA プラットフォームは接続されたすべてのシステムへの直接読み取りアクセスを必要とし、アカウント、グループ、ロール、その他エンタイトルメント、組織構造など、すべてのアイデンティティ関連データを取得・分析します。 IGA プラットフォームは、ポリシー違反を 是正するため、たとえば 孤立したアカウントのアクセスを 無効化するために、必要に応じて情報を書き込みます。
機能を実現するために、IGA プラットフォームは組織全体のアイデンティティデータにアクセスする必要があります。 IGA プラットフォームはアイデンティティ情報を含むすべてのデータベースとデータストアにアクセスしなければなりません。 アクセスは通常コネクターを使って実装され、アプリケーションやデータストアに標準の 通信機構でアクセスします。 IGA プラットフォームは、フィルタリングや変形 のない信頼できるアイデンティティ情報へのアクセスに依存します。 アプリケーションとデータストアへの 直接 接続 は、IGA プラットフォームが適切に機能するためにほぼ常に不可欠です。詳細は 間接アクセス アンチパターン を参照してください。 アイデンティティデータを自分自身のデータベースにストアするアプリケーションは、常に IGA プラットフォームに直接に 接続されるべきです。 LDAP サーバーや Active Directory などのアイデンティティデータストアにあるアイデンティティデータを使い、その情報の永続的なローカルコピーを作らないアプリケーションは、IGA プラットフォームに接続する必要はありません。 しかし IGA プラットフォームは、そのアプリケーションの存在と、LDAP グループなどデータストアエンタイトルメントとアプリケーションとの 関係 を認識しているべきです。
IGA プラットフォームはポリシーエンジンでロールベースのポリシー、ガバナンスポリシー、組織上のポリシーなど、さまざまなポリシーをプロセスします。 ポリシーエンジンは通常プラットフォームの最も複雑な部分の1つです。 ポリシーの大半は 全自動モード で 処理されますが、一部はユーザーや管理者とのやり取りを必要とします。 その目的と他の目的のために、ほぼすべての IGA プラットフォームは 包括的なユーザーインターフェイスを提供します。 ユーザーインターフェイスは通常、次の機能を提供します。
- 一般ユーザー向けのセルフサービスユーザーインターフェイス。 このユーザーインターフェイス部分はアカウントとエンタイトルメントについてユーザーに知らせ、ユーザープロファイルの選択済み部分を管理できるようにし、パスワードなどの認証情報を管理する手段を提供し、アクセス申請の 提出 を可能にします。
- アイデンティティとポリシー管理機能は、アイデンティティ情報の修正と、ロール定義などのポリシー設定を可能にします。 このユーザーインターフェイス部分は、レポートと分析機能を管理し、レポート、分析、ダッシュボードなどの 運用情報の結果にアクセスするためにも使われます。
- 業務プロセスやり取りは、ユーザー、通常マネージャーがアクセス申請承認、認定キャンペーン、是正作業などのアイデンティティ関連業務プロセスに参加するために必要です。 このインターフェイスの一部は サードパーティ ITSM またはワークフローシステムに 委任される場合があります。
- システム設定インターフェイスは低レベルシステム機能を構成するために使われ、通常初期導入やカスタマイズ目的で使われます。 通常はシステム管理者だけがアクセスできます。
IGA プラットフォームは通常 API を提供し、通常は RESTful サービスの形式です。 API はアイデンティティデータ、ポリシー、設定など、IGA プラットフォームが処理するデータを公開 します。 API は通常 IGA 機能へのアクセスを提供しますが、API の機能は製品ごとに大きく異なります。
IGA プラットフォームは通常アイデンティティ関連業務プロセスに参加するため、organization-wide プロセス と 作業管理に使われるシステムと協力してプロセスを管理する要件があります。 通常は IT サービス管理 (ITSM) システムやエンタープライズワークフローエンジンです。 多くの IGA プラットフォームはそのようなシステムと統合し、承認プロセス、是正、類似作業を 委任する機能を持っています。 ITSM システムは手作業フルフィルメント操作を 仲介 するためによく使われます。
機能
アイデンティティガバナンスおよび管理 (IGA) は、業務と技術の両方の必要性によって駆動されます。 組織はそれぞれ異なりますが、多くの組織で非常によく似た形で使われる要件と機能が多数あります。 多くの IGA 製品に共通する基本機能は次のとおりです。
一般的な機構とインフラ
上記の IGA 機能は "tangible" な機能、つまりシステムユーザーにとって明らかな機能を提供します。 しかし、そのような機能を実装するために使われる機構と基盤となる infrastructure は多数あります。 次の機構は、ほぼ常に多くの機能で reused されるため、特定機能に categorize するのが困難です。
- 属性対応付け 機構は属性価値の moving と 変換ing に責任を持ちます。
たとえば HR から取得した属性
LAST_NAMEの価値が、IGA プラットフォームのユーザー プロパティfamilyNameに copied され、それが LDAP 属性snに written されることを処理します。 属性対応付け機構は属性名対応付け、データ形式変換、価値 translation など、データ統合の低レベル詳細をすべて処理します。 この機構は初期移行、リアルタイム同期、照合、フルフィルメント、分析、エンタイトルメント管理などで常に使われます。
- Expressions は価値を変換する必要がある場合、またはアルゴリズムの execution に影響を与える必要がある場合に使われます。 式は通常、JavaScript、Groovy、Python などの well-known スクリプト言語を使った 非常に短いスクリプトコードです。 式の most 一般的利用は、attribute mapping の behavior をカスタマイズし、属性価値がアイデンティティリソースとの間で mapped されるときに変換することです。 しかし式は versatile 機構であり、IGA プラットフォームのさまざまな場所で使われます。 式はロールが付与するエンタイトルメントを 決定し、ABAC 的な動作 を実装できます。 式は承認者や認定者の de解雇、設定の動的 setting、smart ポリシー定義への参加、データ提示とレポートのカスタマイズなど、さまざまなことに使えます。
- スキーマ管理 機構は、接続された各システム、つまりアイデンティティリソースのデータモデル定義を維持します。
LDAP サーバーが 複数値文字列属性
cnとsnを使うこと、HR システムが 単一値文字列属性LAST_NAMEを持つことなどを知っておくのはスキーマ管理の責任です。 このようなアイデンティティリソースのスキーマは通常、アイデンティティコネクターによって自動的に 検出されます。 スキーマ管理は extension 属性、つまりデータモデルカスタマイズの一部として IGA プラットフォームで defined された属性も維持します。 一部の IGA プラットフォームは完全に "schemaless" でスキーマ管理を欠いていますが、一貫した と 保守可能 なシステムを 構築するにはスキーマ管理が通常不可欠です。
- アイデンティティコネクター は、アイデンティティリソース、ソース と 対象システムへの 接続を容易にする小さな統合コードです。 アイデンティティコネクターは通常 IGA プラットフォーム上で running し、ネットワーク経由でアイデンティティリソースにリモートからアクセスします。ただし一部の IGA プラットフォームは、アイデンティティリソースシステムに install しなければならないエージェントをまだ使っています。 コネクターはアカウントやグループなどのオブジェクトを read、作成、更新、削除 (CRUD) する操作を initiate する責任を持ちます。 コネクターはスキーマ 検出プロセスも 仲介 し、同期機構に 連携し、プロビジョニングスクリプトを 実行し、類似の補助操作に参加します。 純粋な形式では、アイデンティティコネクターは本質的にプロトコル適応er であり、IGA プラットフォームの操作を interpret し、それをアイデンティティリソース上で標準のプロトコル、LDAP、SQL、HTTP などを使って 実行します。 コネクターは通常システムに directly アクセスし、標準の形式の unフィルタリング情報を取得して解釈します。 この直接アクセスはデータ fidelity を維持し、データが authentic と 完全であることを保証するために重要です。 この authenticity は孤立したアカウント検知、エンタイトルメント管理、ロールマイニングなどに不可欠です。
- カスタマイズ機構は、ほぼすべての IGA 導入に必要な部分です。 現在の動向は業務プロセスを技術に適応する方向に傾いていますが、それでも各組織ごとに IGA 導入をカスタマイズする必要性は残ります。 組織はそれぞれ異なり、アイデンティティ管理は組織上の fabric の深いところまで入り込みます。 プロセスを standardize することは一般に良い考え方ですが、IGA プラットフォームのある程度のカスタマイズは避けられません。 したがって、すべての IGA プラットフォームは多かれ少なかれ カスタマイズ可能 です。 Behavior を適応でき、ポリシーを設定でき、データフロー を adjust でき、データモデルを extend でき、多くの IGA プラットフォームではユーザーインターフェイスもある程度カスタマイズできます。
- サービス (API) と 統合 は、IGA プラットフォームが他の IT infrastructure システムと 連携するための不可欠機構です。 ほぼすべての IGA プラットフォームは機能を network-accessible インターフェイス (API)、通常は HTTP-based RESTful サービスの形式で expose します。 Exposed API の機能は IGA 製品ごとに異なります。 一部の製品は API-first 方法に基づき、すべての機能を API で expose します。 一方で、ほとんど何の機能も expose しない製品もあります。 大半の IGA 製品はその中間です。 API はプラットフォームの不可欠部分です。 IGA は infrastructure の一部であり、アプリケーションではありません。 したがって IGA は IT プラットフォームに統合される必要があります。 統合の一方の "side" は、アイデンティティコネクターの形式で IGA プラットフォーム自身によって facilitated されます。 しかしもう一方の "side"、つまり API を使って IGA プラットフォームの機能にアクセスする他のアプリケーションやサービスもあります。 したがって API は可用で、reasonable feature-complete、stable、well 文書化 でなければなりません。
- ログ記録 と diagnostics は IGA プラットフォームの操作に不可欠です。 IGA プラットフォームは多くの要件に適応し、多様なポリシーと設定をサポートし、多数のサードパーティシステムに接続 しなければなりません。 したがってプラットフォーム自体、特にプラットフォーム設定はほぼ確実に複雑です。 設定を 初回で動作させることはほぼ 困難 であり、設定は常に新しい要件に合わせて変更・適応する必要があります。 したがって、IGA プラットフォームの良い diagnostic と troubleshooting 機能はソリューションの長期維持管理に絶対的に不可欠です。 構成要素レベルと severity レベルの両方で構造化された comprehensive ログ記録機能は絶対的に不可欠です。 データ内の特定の変更の影響、またはポリシー変更の影響をシミュレートまたは "preview" できる機能も非常に歓迎されます。さまざまな性能 probe や counter も同様です。 残念ながら、多くの IGA プラットフォームは 非常に限られた診断機能しか提供せず、IGA 導入と維持管理を 極めて負担の大きいものにしています。
関連機能
- アクセス制御評価 と 強制、たとえば RBAC/ABAC 評価 と 強制。 IGA はロールベースのアクセス制御 (RBAC) や attribute-based アクセス制御 (ABAC) など、アクセス制御ポリシーの定義と維持管理に関係します。 ロール定義、ロール構造、さらには attribute-based ポリシーの定義も通常 IGA の重要な部分と見なされます。 IGA プラットフォームは通常ポリシー管理 点 (PAP) 機能を実装します。 しかし厳密に言えば、ポリシーの評価と強制は IGA の部分ではありません。 ポリシー、ABAC や RBAC の強制は通常、アプリケーションや infrastructure 構成要素内のポリシー判断 点 (PDP) とポリシー強制 点 (PEP) によって行われます。
- 組織構造管理 は、small でも big でも、ほぼすべての組織にとって crucial 機能です。 組織構造情報は多くの IGA 機能とプロセスに不可欠です。 厳密に言えば、組織上の管理は IGA の部分では なく、IGA ソリューションは組織上の情報を use するだけであるべきです。 組織構造情報は人事(HR)システムなどの専用システムで作成済み と 維持管理されるべきです。 しかし、あまりに多くの組織が組織構造について完全で一貫した機械処理可能な情報を持っていません。 組織構造情報が専用システムで維持管理されているケースでさえ、適切なフィードバックサイクル が欠けています。 組織構造情報は通常、それが作成されたシステム内でしか使われず、業務プロセスや機能における現実世界の検証 の対象になりません。 組織構造データを必要とする他の情報システムは、official 組織構造ソースが提供されたする形式と異なる partial 情報だけを必要とすることがよくあります。 したがって組織構造情報はアプリケーション内で手作業で維持管理されることがよくあります。 IGA プラットフォームはおそらく、その情報を同期、比較、検証しようとする first システムであり、フィードバックサイクルを完成させ、実質的に組織構造管理に参加します。
- 個人データ保護 はアイデンティティガバナンスと密接に関連しています。 まだアイデンティティガバナンスおよび管理の部分として 正式に認識 されてはいませんが、IGA の多くの 側面 に permeate しています。 GDPR などのデータ保護 とプライバシーフレームワークは、法的根拠 がある場合にのみ個人データをプロセスできると mandate しています。 したがって処理 basis は、アイデンティティごと、さらにはデータ項目ごとに individually tracked されなければなりません。 これは柔軟情報環境では easy 作業ではありません。さまざまなアイデンティティ種類が mix し、1つのアイデンティティが多くの目的やロールに使われることが多いからです。 同意は可能な処理根拠 の1つです。 しばしば misused されますが、ユーザーがいつでも consent を revoke できる可能性を考慮し、consent 情報は strictly tracked される必要があります。 処理根拠 に加えて、個人データの 来歴 も追跡されなければならず、個人データの 移転、特に他の組織や国への移転 は制御される必要があります。 データは不要 になった時点で消去 されなければなりません。